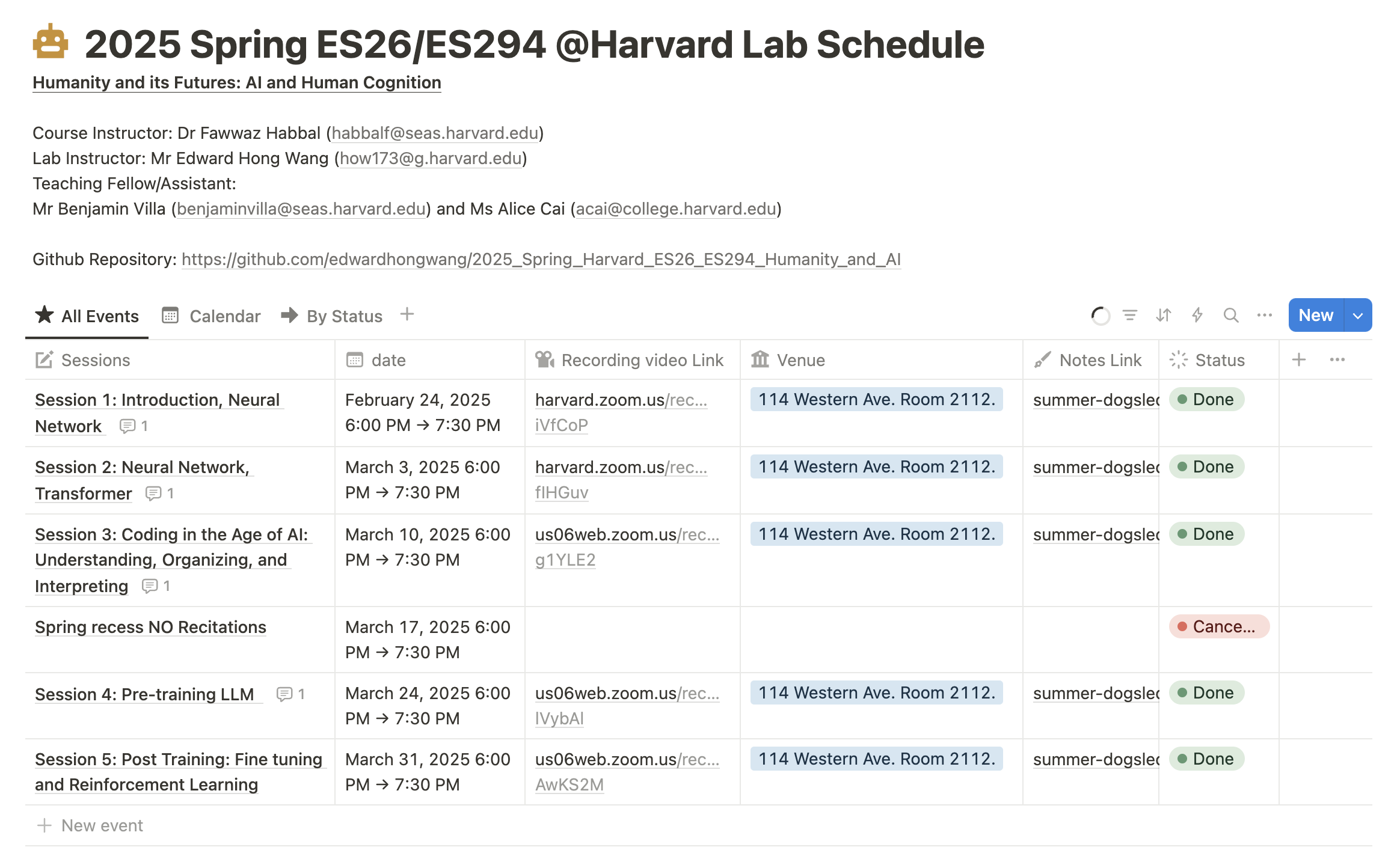
Hi, I'm Edward Hong Wang, a Junior Researcher at Harvard University, working closely with Dr. Fawwaz Habbal. Together, we are co-teaching ES26/ES294 at Harvard SEAS in Spring 2025, a groundbreaking course exploring the intersections between Human Cognition and Artificial Intelligence.
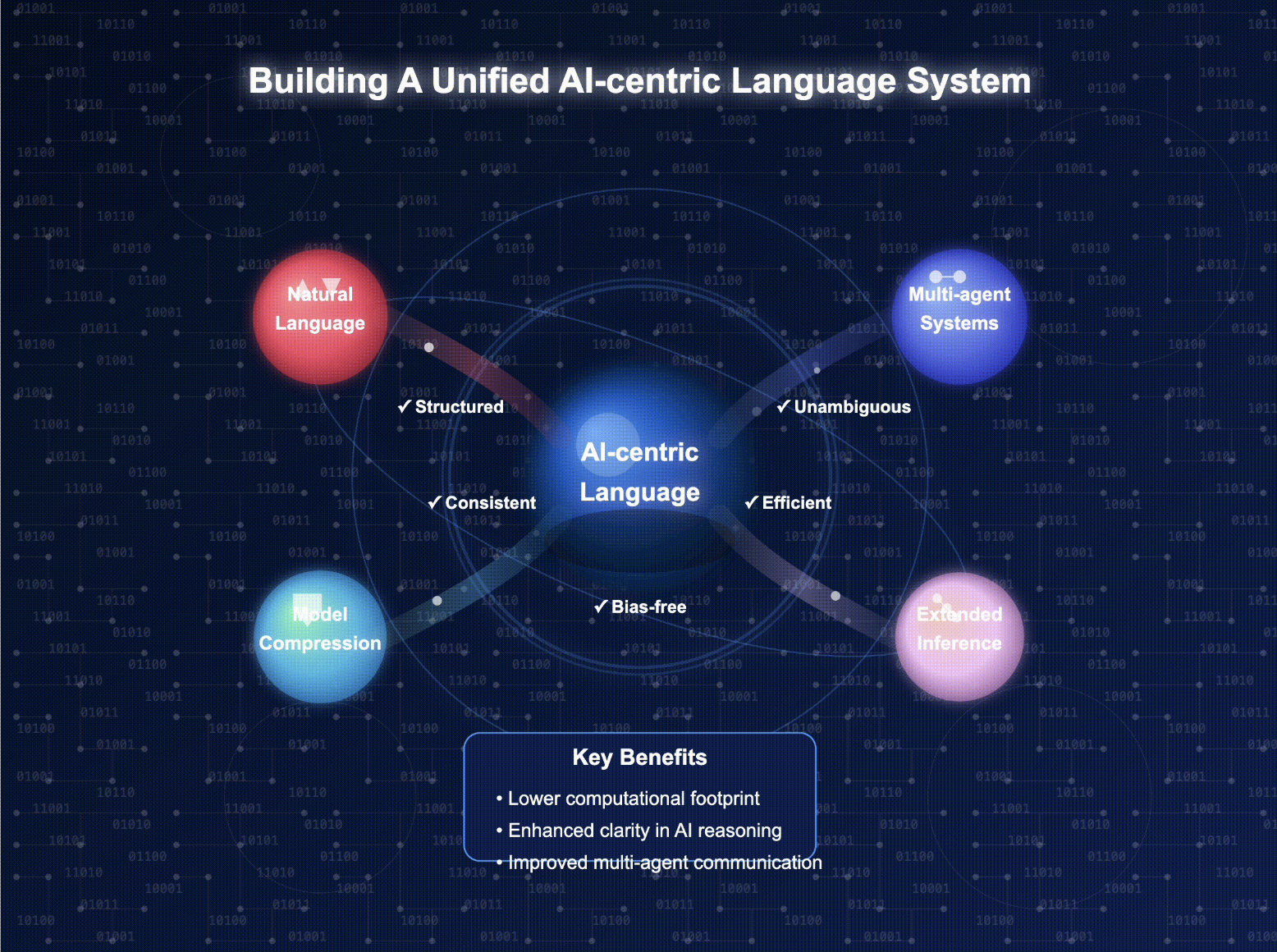
My research focuses primarily on Multi-Modal Large Language Models (LLMs) and their impactful applications across diverse fields such as Neuroscience, Robotics, Quantum Physics, and Collaborative Behavior. I'm passionate about leveraging these advanced technologies to facilitate interdisciplinary breakthroughs.
I'm currently seeking collaborators interested in pioneering research. Active projects include:
- Neural Implant, Smart Wearable, and Multimodal LLM integration
- HTML-to-Matrix Browser Interaction
- Transfusion: Diffusion Models combined with Transformer Architectures
- Emergent Collaborative Behaviors in Multi-Agent Systems through Reinforcement Learning
- Quantum Error Correction using Neural Networks enhanced by Reinforcement Learning